

 Five signs your spreadsheet might smell (and what you can do about it)" style="object-fit: cover;object-position: center;width:100%;height:100%;" fetchpriority="high" decoding="sync"/>
Five signs your spreadsheet might smell (and what you can do about it)" style="object-fit: cover;object-position: center;width:100%;height:100%;" fetchpriority="high" decoding="sync"/>
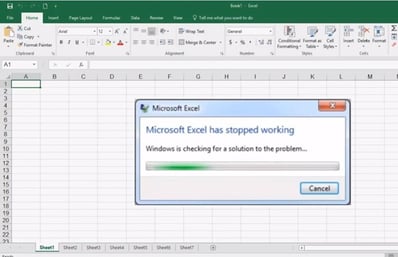 Single-user databases: a single file stores all the data, only requiring an application to open the database file, popular options include SQLite and Microsoft Access. These kinds of databases are great if only one user needs to access the data, but can fall into some of the pitfalls outlined below if there are multiple users and different data versions.
Single-user databases: a single file stores all the data, only requiring an application to open the database file, popular options include SQLite and Microsoft Access. These kinds of databases are great if only one user needs to access the data, but can fall into some of the pitfalls outlined below if there are multiple users and different data versions.- Multi-user relational database management system (RDMS): these typically run on a server and are designed to support lots of people viewing and editing the data at the same time, common examples include PostgreSQL, MySQL or Microsoft SQL Server.
Databases focus on data storage, and SQL enables queries and simple calculations on the data, but typically the presentation of this data will require something like Power BI or a web application.
 Version hell
Version hell
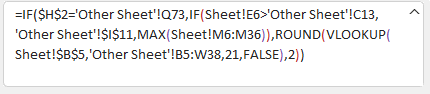
Solutions
For the examples above:
 Representing spatial information in a non-spatial way: carefully think through your solution – if you may later want to show the data on a map or do spatial analysis on it: use spatial tools from the outset. Data can always be presented without a spatial component down the line, but it can be difficult to add spatial information retrospectively.
Representing spatial information in a non-spatial way: carefully think through your solution – if you may later want to show the data on a map or do spatial analysis on it: use spatial tools from the outset. Data can always be presented without a spatial component down the line, but it can be difficult to add spatial information retrospectively.- Spatial analysis: spatially aware applications, like ArcGIS or QGIS, are fundamentally designed to project between different coordinate systems, include a wide range of spatial analysis tools “out of the box” and can be readily customised to chain operations together.
- Data transfer: in some situations it may be possible to export directly between systems (or there may be a data exchange format available that is more appropriate than spreadsheets), otherwise spatially-enabled tools such as FME specialise in this “extract, transform, load” workflow, reading from and writing to a wide variety of systems and data sources, and enabling a wide array of transformations to be performed on data in the process.